SASユーザー総会2023で「SASによる散布図行列の実装」っていう素晴らしい発表があって
https://sas-user2023.ywstat.jp/download.html?n=36&key=ensdaeeadcsr
それが呼び水となって
SASブログの方で
「SASで散布図行列を作図する -layout latticeの仕様について-」
https://superman-jp.hatenablog.com/entry/SAS-GTL-scatterplotmatrix
や
「新しい散布図行列の作成法Ⅰ」
https://sasonediver.blog.fc2.com/blog-entry-531.html
があがって,なんなの,今はプロットマトリクス作るのがブームなの笑
ってことで,ちょっと,ついでにオマケ情報で 違う作り方を
SAS Oneブログさんの方の「新しい散布図行列の作成法Ⅰ」とおんなじで,とりまSGで作ってそれを貼り合わせてもいいんじゃない?って時に Python呼び込んでも全然ありと思うのですが,私はRWIが楽と思ってます
ほんと楽で…
もうプロットの部分は皆さんがやってるので,特に言いたいことはないので,合成法だけ

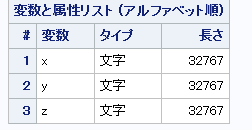
👆これをつかって3*3のプロットマトリクスにしてみますね
options printerpath=png nodate nonumber papersize=('15cm' ,'15cm') ;
ods printer file='XXX\TEST.png' nogtitle dpi=500;
title;
data _NULL_;
dcl odsout ob();
ob.layout_gridded( columns:3, rows:3 );
ob.region();
ob.image( file: "XXX\PharmaSUG.png" );
ob.region();
ob.image( file: "XXX\PharmaSUG.png" );
ob.region();
ob.image( file: "XXX\PharmaSUG.png" );
ob.region();
ob.image( file: "XXX\PharmaSUG.png" );
ob.region();
ob.image( file: "XXX\PharmaSUG.png" );
ob.region();
ob.image( file: "XXX\PharmaSUG.png" );
ob.region();
ob.image( file: "XXX\PharmaSUG.png" );
ob.region();
ob.image( file: "XXX\PharmaSUG.png" );
ob.region();
ob.image( file: "XXX\PharmaSUG.png" );
run;
ods printer close;

ob.layout_gridded( columns:3, rows:3 );
👆ここでマトリクス構造を指定したら
あとは
ob.region();
ob.image( file: "XXX\PharmaSUG.png" );
で順番に画像ファイルを指定するだけ
チョー簡単